1 Hadoop介绍与安装
Hadoop简要概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop HDFS配置
根目录结构
.
├── bin #存放hadoop各类程序
├── etc #配置文件
├── include #源代码
├── lib #动态链接库
├── libexec # 脚本
├── licenses-binary #许可文件
├── sbin #super bin 管理员程序
└── share #二进制代码,jar包
8 directories
修改文件
修改/etc/hadoop下的文件
- workers 配置从节点有哪些
- hadoop-env.sh 环境变量
- core-site.xml hadoop核�心配置文件
- hdfs-site.xml hdfs核心配置文件
workers
[root@node1 hadoop]# cat workers
node1
node2
node3
hadoop-env.sh
添加以下路径
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
同时你需要在node1上新建文件夹/data/nn 与 /data/dn,node2,node3建立/data/dn
分发
通过远程ssh分发hadoop软件到node2、node3
scp -r hadoop node2:`pwd`/
scp -r hadoop node3:`pwd`/
在node2与node3执行软链接
ln -s /export/server/hadoop-3.3.5 ./hadoop
配置环境变量
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
权限分配给hadoop用户
[root@node1 server]# chown -R hadoop:hadoop /data
[root@node1 server]# chown -R hadoop:hadoop /export
[root@node1 server]# ll
总用量 8
lrwxrwxrwx 1 hadoop hadoop 28 6月 13 12:36 hadoop -> /export/server/hadoop-3.3.5/
drwxr-xr-x 10 hadoop hadoop 4096 3月 16 00:58 hadoop-3.3.5
lrwxrwxrwx 1 hadoop hadoop 28 6月 13 12:07 jdk -> /export/server/jdk1.8.0_371/
drwxr-xr-x 8 hadoop hadoop 4096 6月 13 12:06 jdk1.8.0_371
[root@node1 server]# cd /data
[root@node1 data]# ll
总用量 0
drwxr-xr-x 2 hadoop hadoop 6 6月 13 13:24 dn
drwxr-xr-x 2 hadoop hadoop 6 6月 13 13:24 nn
[root@node1 data]#
启动
格式化文件系统
确保在hadoop用户下执行
[root@node1 ~]# su - hadoop
[hadoop@node1 ~]$ hadoop namenode -format
WARNING: Use of this script to execute namenode is deprecated.
WARNING: Attempting to execute replacement "hdfs namenode" instead.
WARNING: /export/server/hadoop/logs does not exist. Creating.
...
格式化后会在文件夹/data/nn出现以下内容
drwx------ 2 hadoop hadoop 112 6月 13 13:43 current
[hadoop@node1 nn]$ cd current/
[hadoop@node1 current]$ ll
总用量 16
-rw-r--r-- 1 hadoop hadoop 401 6月 13 13:43 fsimage_0000000000000000000
-rw-r--r-- 1 hadoop hadoop 62 6月 13 13:43 fsimage_0000000000000000000.md5
-rw-r--r-- 1 hadoop hadoop 2 6月 13 13:43 seen_txid
-rw-r--r-- 1 hadoop hadoop 217 6月 13 13:43 VERSION
[hadoop@node1 current]$
启动程序
[hadoop@node1 ~]$ start-dfs.sh
Starting namenodes on [node1]
Starting datanodes
node2: WARNING: /export/server/hadoop/logs does not exist. Creating.
node3: WARNING: /export/server/hadoop/logs does not exist. Creating.
Starting secondary namenodes [node1]
# 后台java运行程序
[hadoop@node1 ~]$ jps
11969 SecondaryNameNode
12263 Jps
11388 NameNode
11580 DataNode
启停管理命令
一键启停
- start-dfs.sh 一键启动HDFS集群
- stop-dfs.sh 一键关闭集群
单进程启停
- hadoop-daemon.sh (start | status | stop) (namenode | secondarynamenode | datanode)
- hdfs --daemon (start | status | stop) (namenode | secondarynamenode | datanode)
[hadoop@node1 ~]$ hadoop-daemon.sh stop datanode
WARNING: Use of this script to stop HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon stop" instead.
[hadoop@node1 ~]$ hdfs --daemon stop secondarynamenode
[hadoop@node1 ~]$ jps
15318 Jps
11388 NameNode
[hadoop@node1 ~]$ hdfs --daemon start secondarynamenode
[hadoop@node1 ~]$ hdfs --daemon start datanode
[hadoop@node1 ~]$ jps
15713 Jps
15604 DataNode
15479 SecondaryNameNode
11388 NameNode
[hadoop@node1 ~]$
FS Shell
两条重要前缀:
hdfs: Hadoop Distributed File System
hadoop fs <args>
hdfs dfs <args>
- 创建文件夹 :
hadoop fs/hdfs dfs -mkdir -p <psth> - 查看目录下文件:
hadoop fs/hdfs dfs -ls [-h] [-R] <psth> - 上传文件到HDFS指定目录
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
# -p 覆盖目标文件
# -p 保留文件属性
- 查看文件cat :
hadoop fs/hdfs dfs -cat <psth> | more - 下载文件:
hadoop fs/hdfs dfs -get [-f] [-p] <src> ... <localdst> - 追加数据到文件中:
hadoop fs/hdfs dfs -appendToFile <localsrc> ... <dst> - 删除文件:
hadoop fs/hdfs dfs -rm -r [-skipTrash] URL [URL ...]
启用回收站功能(core-site.xml)
<property>
<name>fs.trash.interval</name>
<value>1440</value> %%保留一天%%
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
回收结果:
[hadoop@node1 ~]$ hadoop fs -rm -r /home
2023-06-13 14:53:15,100 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/home' to trash at: hdfs://node1:8020/user/hadoop/.Trash/Current/home
[hadoop@node1 ~]$ hadoop fs -ls -R /
drwx------ - hadoop supergroup 0 2023-06-13 14:53 /user
drwx------ - hadoop supergroup 0 2023-06-13 14:53 /user/hadoop
drwx------ - hadoop supergroup 0 2023-06-13 14:53 /user/hadoop/.Trash
drwx------ - hadoop supergroup 0 2023-06-13 14:53 /user/hadoop/.Trash/Current
drwxr-xr-x - hadoop supergroup 0 2023-06-13 14:23 /user/hadoop/.Trash/Current/home
drwxr-xr-x - hadoop supergroup 0 2023-06-13 14:23 /user/hadoop/.Trash/Current/home/hadoop
网页查看文件
网站端口:localhost:9870
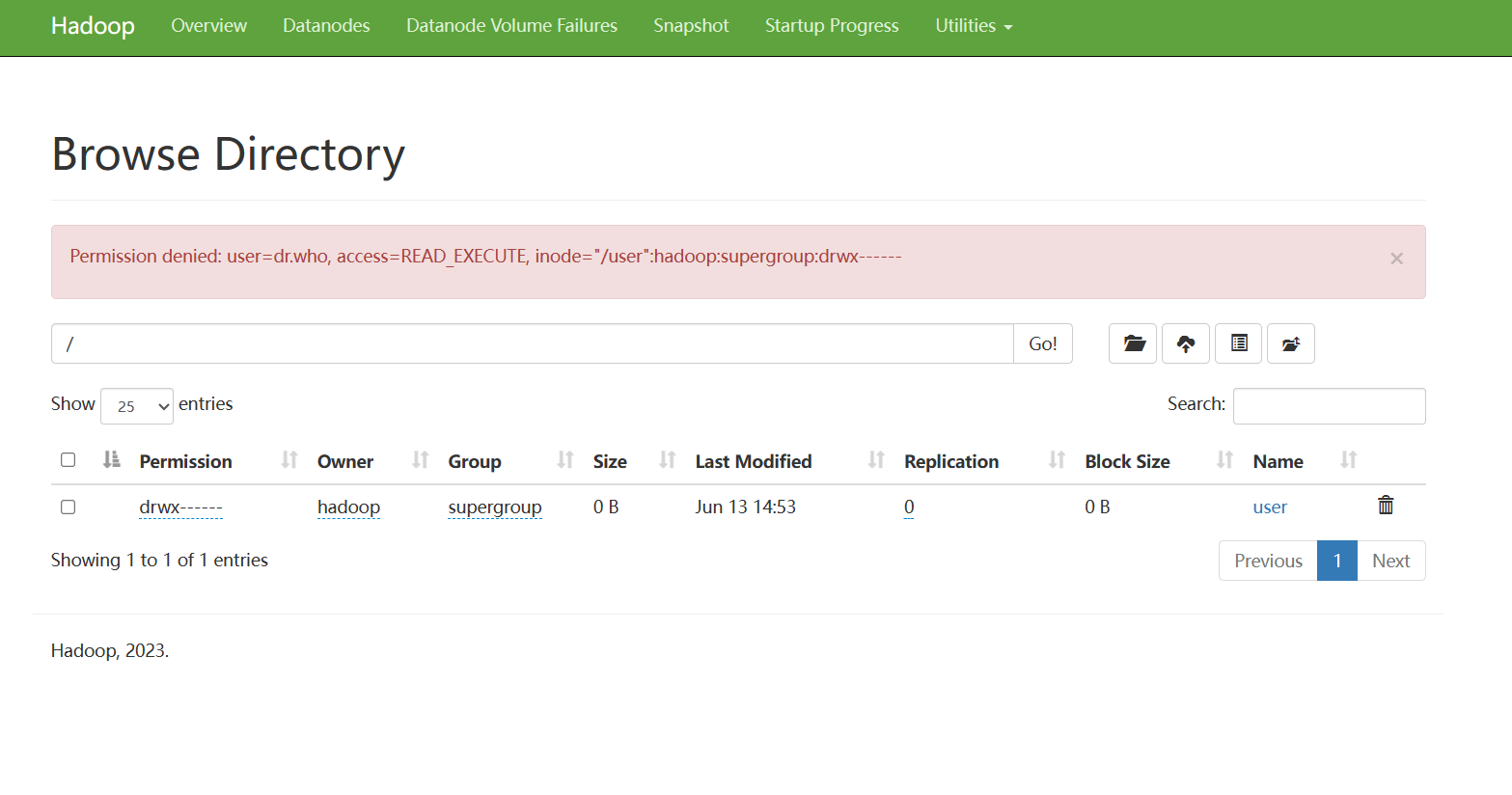
这里问什么会出现
Permission denied: user=dr.who因为我们在浏览网页的时候相当于是匿名用户,没有权限。
也可在配置文件修改权限(core-site.xml),需要重启集群:
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
不推荐可以给网页浏览加以高权限,有很大的安全问题,造成数据的泄露与丢失
配置NFS
network files system
添加 core-site.xml 配置
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
proxyuser.hadoop.groups 允许代理任何用户组 proxyuser.hadoop.hosts 允许代理任意服务器请求
添加 hdfs-site.xml 配置
<property>
<name>nfs.superuser</name>
<value>hadoop</value>
</property>
<property>
<name>nfs.dump.dir</name>
<value>/temp/.hdfs-nfs</value>
</property>
<property>
<name>nfs.exports.allowed.hosts</name>
<value>192.168.3.1 rw</value>
</property>
proxyuser.hadoop.groups 允许代理任何用户组 proxyuser.hadoop.hosts 允许代理任意服务器请求
启动nfs
- 分发以上配置好的文件
- 重启集群
- 停止系统原先自带的nfs相关进程,同时卸载掉自带的
rpcbind
yum remove -y rpcbind
- 启动portmap:
hdfs --daemon start portmap(要在root下执行) - 启动nfs:
hdfs --daemon start nfs3(在hadoop下执行)
windows挂载nfs: net use X: \192.168.3.133!
启动与停止脚本
一键启动脚本
请根据需求修改:
software,hadoop,spark的可执行路径
#!/bin/bash
software="/export/server"
hadoop="$software/hadoop"
spark="$software/spark"
log_file="$software/logs/startlogs/$(date +%Y-%m-%d_%H-%M-%S).log"
if jps | grep -q "NameNode"; then
echo "Hadoop已经在运行"
else
echo "正在启动你的集群,默认软件路径为$software --"
sleep 1s
echo "正在启动hadoop------------------------"
start-dfs.sh 2>&1 | tee -a $log_file
fi
if jps | grep -q "ResourceManager"; then
echo "Yarn已经在运行"
else
echo "正在启动yarn--------------------------"
start-yarn.sh 2>&1 | tee -a $log_file
fi
if jps | grep -q "JobHistoryServer"; then
echo "历史服务器已经在运行"
else
echo "启动hadoop与yarn成功,正在启动历史服务器---"
mapred --daemon start historyserver 2>&1 | tee -a $log_file
fi
if jps | grep -q "Master"; then
echo "Spark已经在运行"
else
echo "正在启动spark-------------------------"
sleep 1s
$spark/sbin/start-history-server.sh 2>&1 | tee -a $log_file
$spark/sbin/start-all.sh 2>&1 | tee -a $log_file
fi
echo "集群全部已经启动成功!"
一键关闭脚本
请根据需求修改:
software,hadoop,spark的可执行路径
#!/bin/bash
# Set the log file name
software="/export/server"
hadoop="$software/hadoop"
spark="$software/spark"
log_file="$software/logs/stoplogs/$(date +%Y-%m-%d_%H-%M-%S).log"
# Stop Spark and save the output to the log file and print to the console
if jps | grep -q "Master"; then
$spark/sbin/stop-all.sh 2>&1 | tee -a $log_file
$spark/sbin/stop-history-server.sh 2>&1 | tee -a $log_file
else
echo "Spark已经停止"
fi
# Stop MapReduce history server and save the output to the log file and print to the console
if jps | grep -q "JobHistoryServer"; then
mapred --daemon stop historyserver 2>&1 | tee -a $log_file
else
echo "历史服务器已经停止"
fi
# Stop YARN and save the output to the log file and print to the console
if jps | grep -q "ResourceManager"; then
stop-yarn.sh 2>&1 | tee -a $log_file
else
echo "Yarn已经停止"
fi
# Stop HDFS and save the output to the log file and print to the console
if jps | grep -q "NameNode"; then
stop-dfs.sh 2>&1 | tee -a $log_file
else
echo "Hadoop已经停止"
fi